
dpdk
叠嶂西驰,万马回旋,众山欲东。正惊湍直下,跳珠倒溅;小桥横截,缺月初弓。老合投闲,天教多事,检校长身十万松。吾庐小,在龙蛇影外,风雨声中。
争先见面重重,看爽气朝来三数峰。似谢家子弟,衣冠磊落;相如庭户,车骑雍容。我觉其间,雄深雅健,如对文章太史公。新堤路,问偃湖何日,烟水濛濛?
Linux传统网络驱动流程
- 数据包到达网卡设备
- 网卡设备通过DMA将收到的数据放入内存
- 网卡驱动触发中断,唤醒处理器
- 驱动软件填充读写缓冲区数据结构
- 数据报文到达内核的协议栈,进行处理
- 如果最终应用在内核态,则继续处理数据;如果最终应用在用户态,则需要将数据拷贝到用户态
DPDK的特点
- 轮询而非中断,采用轮询的方式,避免的中断切换的开销。有利于大吞吐数据的处理。
- 用户态驱动, 采用了用户态驱动的方式,避免了系统调用和数据的拷贝。
- 亲和性与独占,线程的调度依赖于内核,可以将特定的任务指定在某个核上工作,从而避免线程间切换的开销以及线程切换造成的缓存缺失。
- 降低访存开销,使用内存大页来减小页表,从而使得TLB的缺失率降低。
- 数据对其,cache line等数据结构会要求对其。
- 充分利用硬件性能,充分利用SIMD等技术以及网卡加速。
DPDK的基本架构
dpdk的基本架构图如下所示:
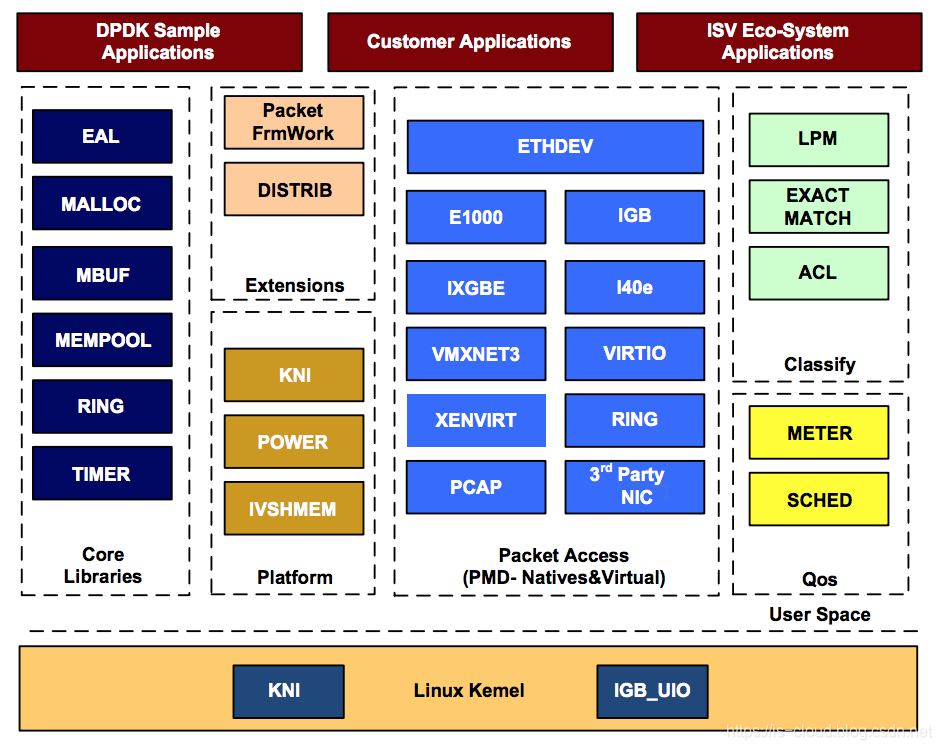
dpdk由很多的组件库组成,主要包括核心部件库(core libararies)、平台相关模块(platform)、网卡轮询模式驱动模块(PMD-natives & virtual)、QoS库、报文转发分类算法(classify)等。
位于linux kernel中的两个模块 KNI 和 IGB_UIO 。其中 KNI 提供了使用linux kernel的内核协议栈和一些网络工具的接口。而 IGB_UIO 则利用了UIO(linux User IO)技术,将网卡硬件寄存器映射到用户态。
核心部件库(core libraries)
如上图所示,该模块通过环境抽象层EAL(enviroment abstraction layer)进行运行环境的初始化。EAL实现了对操作系统内核与底层网卡IO操作的屏蔽,旁路的内核及其协议栈。MALLOC提供了大页内存分配,MBuf实现了内存的封装,主要用来储存网络帧的缓存。Mempool则主要用于内存管理,内存操作对象被抽象化为Mbuf结构,mempool则主要用于管理Mbuf。ring是一个无锁环形队列,空间大小固定,并且支持批量入队和批量出队。timer用于定时器。
平台相关模块(platform)
该模块主要包括KNI、power、IVSHMEN接口。KNI将数据报文从用户态传递给内核协议栈处理,以便使得用户进程可以使用传统的Socket接口对报文进行处理。power模块出于节能考虑会进行运行时频率调整。IVSHMENM则提供了虚拟机和虚拟机之间的共享内存。
轮询模式驱动模块(PMD库)
提供全用户态的驱动,通过轮询和线程绑定得到更大的吞吐量。避免了传统中断方式造成的切换开销。
报文分类算法(classify)
提供了精确匹配(EXACT MATCH)、最长匹配(LPM)和通配符匹配(ACL),同时提供了常用的包处理操作。
QoS库
提供了网络服务质量相关组件,如限速(meter)和调度(sched)
扩展库(extensions)
为更复杂的多核流水线处理模型提供了基础的组件
DPDK用到的一些技术
保证cache一致性
避免多个核访问同一个内存地址。对于某些需要共享的数据结构,可以对每个核都拷贝一份。对于网卡数据的读写,可以给每个核都准备一个单独的接收队列和发送队列。
巨页技术
linux一般采用4K的页面,为了减小页表的尺寸,从而提高TLB的命中率,可以使用2MB乃至1G的页面。
轮询技术
不同于传统的中断技术来处理IO,DPDK采用了轮询的技术,能够减少中断的开销,提高效率。
CPU亲和技术
尽量使得某个线程固定在一个核上运行,可以消除线程切换带来的开销。可以使用linux的pthread库来实现亲和性绑定。
内存多通道
dpdk的mempool库将对象分配到不同的内存通道上,以免所有的访问都发生在某一个内存通道上造成性能损失。
NUMA架构(Non Uniform Memory Access 非统一内存访问)
每个处理器有自己的本地内存,处理器访问自己的本地内存有更小的延迟核更大的带宽。跨处理器的内存访问会相对慢一些。
核间无锁通信
可以使用DPDK中的无锁环形队列ring来实现核间的无锁通信。







